テキスト、画像、映像、音楽等のさまざまなメディアを対象とした高速検索アルゴリズ
ムや情報検索技術について研究を進めており、商用サービスで用いられている技術
も数多く開発しています。代表的な研究を以下に示します。
1.高速な検索アルゴリズムに関する研究
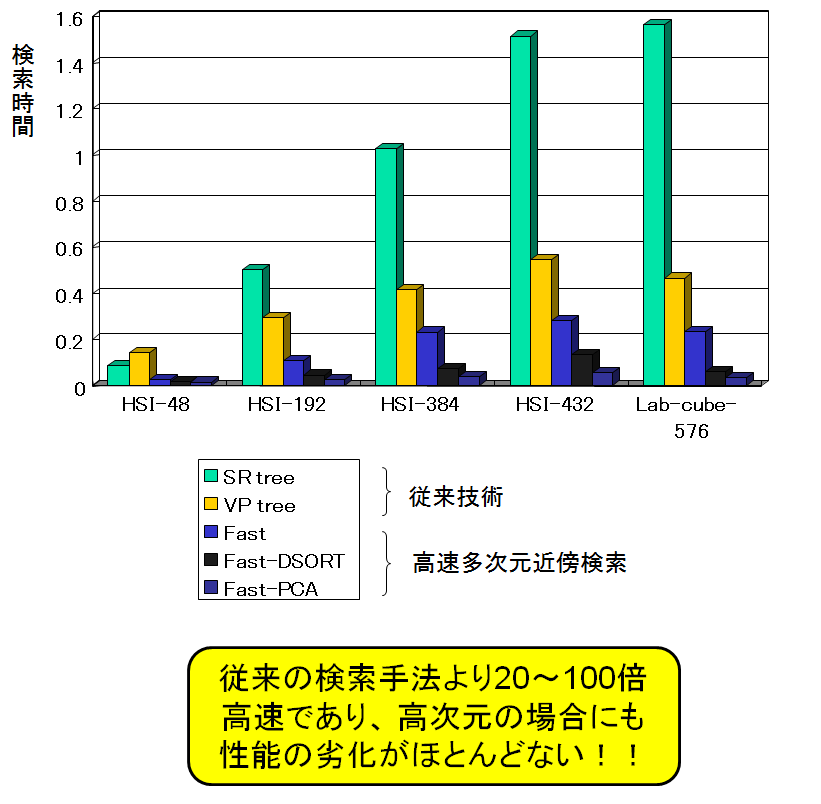
世界最高速の多次元データ検索アルゴリズム、Earth Mover’s Distanceに対す
る高速検索アルゴリズム、ハミング空間の高速検索アルゴリズム(特許出願中)、ヒ
ント機能を備えたテキスト検索アルゴリズムなど、効率的なマルチメディア・コンテン
ツ検索を実現するうえで必須の高速検索アルゴリズムの研究開発を行っています。
|
2.ビット演算に基づく高速な近似文字列照合に関する研究
文書検索において、検索対象に含まれる人的誤りがあると、キーワードとの完全一致による検索が
困難となる。そのため、近似文字列照合技術が提案されてきた。しかし、従来手法の多くは、
文字列間の距離として編集距離を動的計画法で計算していたため、時間的・空間的コストが高い。
本研究では、文字列をビット列に変換することで、検索インデックスの大幅な容量削減および、
検索速度の向上を目指す。
|
3. 聞き間違いと記憶間違いに着目した歌詞検索アルゴリズム
歌詞検索における問題点として、通常の文書検索とは異なるものがある。たとえば、
歌詞は、一般的な文書と異なり、含まれる単語数が少ないわりにサビ部分のような
繰り返しが多かったり、通常の文書よりも比喩的(特に隠喩)な表現が多く含まれるため、
既存の類似度計算や意味辞書を用いることが必ずしも有効とは限らない。
また、歌詞は、その多くは曲を聴いて記憶することが多いため、当然ながら
聞き間違いや記憶間違いが生じやすい。そのため、うろ覚えの歌詞片を用いた検索を
Googleなどの既存の検索エンジンで行ったとしても、求めている歌詞情報が得られない場合がある。
本研究では、入力歌詞片に含まれる聞き間違いや記憶間違いを考慮して、妥当な検索結果が
得られるような歌詞検索システムを開発することを目的としている。
|
4. 擬音語検索に関する研究
オノマトペのなかでも、擬音語は、音を表現するものであるため、
実際に耳にしたことのある音と似ているはずです。
その類似性を考量することで、効果音を検索するための第一段階として、
擬音語間の類似度を考慮した類似擬音語の検索手法について研究しました。
既存手法でも用いられていた音象徴のみでは、擬音語の意味的な情報が
得られないため、同じ擬音語でもどちらの意味で用いられているかが分からないと
検索精度を向上させることができません。本研究では、擬音語検索の際に、
連想キーワードなどの情報を付加することで、意味的な類似度も考慮した
手法を提案しました。評価実験の結果、従来手法を大幅に上回る精度での
擬音語検索を実現できました。
|